I am an enthusiastic Data Engineer with a can-do approach to all data-related challenges. I am always learning new things related to data technologies and developments. Creating lots of advanced Python scripts and writing many advanced SQL queries. Creating both batch and streaming data pipelines with many data tools and frameworks.
Take a compressed data source from a URL Process the raw data either with PySpark or Pandas and use HDFS as the file storage, check resources with Apache Hadoop YARN. Use a data generator to simulate streaming data, and send the data to Apache Kafka (producer). Read the streaming data from the Kafka topic (consumer) using PySpark (Spark Structured Streaming). Write the streaming data to Elasticsearch, and visualize it using Kibana. Write the streaming data to MinIO (AWS Object Storage). Use Apache Airflow to orchestrate the whole data pipeline. Use Docker to containerize Elasticsearch, Kibana, and MinIO.
Scrape the data from a website and save it as JSON. Send the JSON data record by record (EC2) to a Kinesis Data Stream and buffer in Firehose. Upload the file to the S3 bucket and trigger the Lambda function. Lambda function converts it to parquet. After uploading to another S3 bucket, trigger Glue workflow. Create a Glue table with Crawler and run the Glue ETL Job. After cleaning the data, upload it to S3 bucket and create a Glue table. Create a QuickSight dashboard using Redshift and Athena in the end.
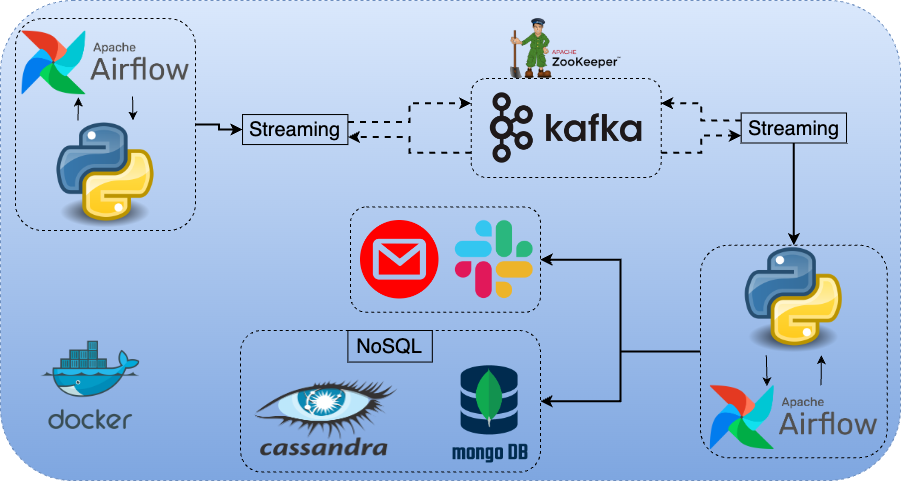
Create a streaming pipeline. Send the data into a Kafka topic by creating it. Consume the data both for Cassandra and MongoDB. Check if a specific e-mail exists. If so, send e-mail and Slack message using Airflow operators.
We are going to create a data pipeline in this project. We are going to upload a remote CSV file into the S3 bucket automatically with Python and Shell scripts running in an EC2 instance. Then, we are going to create a Lambda function using a container image. Once the CSV file is uploaded to the S3 bucket, the Lambda function will be triggered. The main target of the Lambda function will be modifying the CSV data and fixing the errors. We are going to create an RDS database as well and will upload the modified data into a table inside this database. Once the upload is completed, we will be able to monitor the data using DBeaver and we will connect to RDS using an SSH tunnel via EC2 user.
We will use Random Name API to get the data. It generates new random data every time we trigger the API. We will get the data using our first Python script. We will run this script regularly to illustrate the streaming data. This script will also write the API data to the Kafka topic. We will also schedule and orchestrate this process using the Airflow DAG script. Once the data is written to the Kafka producer, we can get the data via Spark Structured Streaming script. Then, we will write the modified data to Cassandra using the same script. All the services will be running as Docker containers.
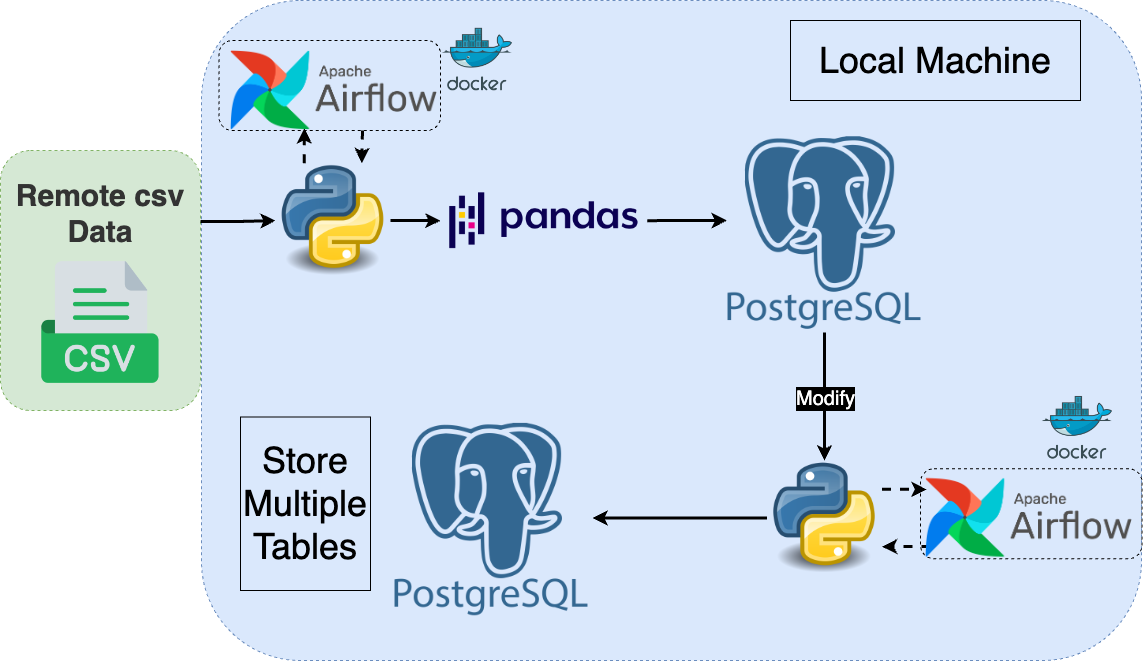
In this project, we are going to get a CSV file from a remote repo, download it to the local working directory, create a local PostgreSQL table and write this CSV data to the PostgreSQL table with write_csv_to_postgres.py script. Then, we will get the data from the table. After some modifications and pandas practices, we will create 3 separate data frames with create_df_and_modify.py script. In the end, we will get these 3 data frames, create related tables in the PostgreSQL database and insert the data frames into these tables with write_df_to_postgres.py
With this project, we will create an EC2 instance with suitable IAM roles attached. We are going to also create an RDS MySQL database. We are going to write a code with either Jupyter Lab or as a Python script and this code will upload a remote CSV file into an S3 bucket, then it will get the data from the bucket, modify it and upload the modified data into the RDS MySQL database as a table. In the end, we will monitor the uploaded data using DBeaver. We will go through both options: Jupyter Lab and Python script.
Creating Pub/Sub topic to be used by both Google Functions and Google Scheduler. Creating a new Google function to run both scripts in the Google Cloud environment. Creating a new job for Google Scheduler to run the script regularly
We are going to create both serverless and provisioned Amazon MSK clusters. Then, we will create an EC2 instance where we will be running our consumer and producer as bash commands. We are going to create bash commands which will create a new topic, send the messages we will be writing line by line to this topic (producer) and consume the messages on the console.
We will be illustrating a streaming data pipeline with this project. crypto_data_stream.py gets BTC prices from Crypto API (provided by CoinMarketCap) with an API key. The same script also sends the price-related data to the Kafka topic (producer) every 10 seconds using Airflow for a time period of 3 minutes. We are going to schedule the jobs using Airflow DAGs with crypto_data_stream_dag.py. Once the data is written to Kafka, we will get the data from the Kafka topic (consumer) with read_kafka_write_mysql.py. Once the data is written to the MySQL table, we will connect Metabase to MySQL and create a real-time dashboard in the end.
In this project, we will first create a new S3 bucket and upload a remote CSV file into that S3 bucket. We are going to create a Data Catalog using either Crawler or a custom schema. Once all is created, we are going to create a new Glue ETL Job. We are going to go through both options: Spark script and Jupyter Notebook. We will do some transformations using Spark. Once our data frame is clear and ready, we will upload it as a parquet file to S3 and will create a corresponding Data Catalog as well. We are going to query the data using Athena and S3 Select. We will also schedule the job so that it runs on a regular basis.
In this project, we are going to upload the CSV data into an S3 bucket either with automated Python/Shell scripts or manually. After creating the EMR cluster, we are going to run a Spark job with Zeppelin Notebook and modify the data. After modifications, we are going to write the data to S3 as a parquet file. A Glue Data Catalog table will also be created. We will monitor the data using AWS Athena in the end.